

Rust vs Go vs Python for AI Agents & Applications
The real answer isn’t which language is best. It’s which layer of your agent stack each language belongs in — and why choosing wrong costs you at scale.
⚙️ Rust · Systems Layer | 🐹 Go · Orchestration Layer | 🐍 Python · Intelligence Layer
The Question Nobody Is Asking Correctly
Every few months, a thread appears — “Should I build my AI agent in Rust, Go, or Python?” — and it immediately collapses into a benchmark war that misses the point entirely.
The practitioners who are actually shipping AI applications at scale are not choosing one language. They are building polyglot systems where each language owns the layer it was designed for. Anthropic writes inference infrastructure in Rust. OpenAI’s API gateway runs on Go. The agent frameworks developers love — LangChain, CrewAI, AutoGen — are Python all the way down.
This is not accidental. It reflects a deep truth about how AI agent systems are structured—they have fundamentally different concerns at different layers, and those concerns map precisely onto what each language was built to do.
“The question is not which language is best for AI agents. The question is which layer of your agent stack you are building right now.”
This article cuts through the noise. We will examine all three languages against the specific demands of AI agent engineering: concurrency model, memory behaviour, ecosystem depth, error semantics, deployment characteristics, and—critically—how each fits into the layered architecture that modern agent systems require.
The AI Agent Stack and Where Each Language Lives
Before comparing languages, we need to establish the architecture. A production AI agent system is not a monolith—it is a layered pipeline with distinct engineering requirements at each layer.
| Layer | Responsibilities | Best Choice |
|---|---|---|
| 🧠 Intelligence Layer | LLM calls, prompt engineering, chain/graph orchestration, memory retrieval, tool selection | Python Wins |
| 🔀 Orchestration Layer | API gateway, agent loop runner, tool routing, concurrency management, streaming SSE/WebSocket | Go Wins |
| ⚙️ Runtime Layer | Tokenisation, embedding computation, vector similarity search, in-process inference, WASM edge agents | Rust Wins |
🐍 Python — The Intelligence Layer
Python’s dominance in AI is not a coincidence of history — it is a compound moat built over a decade. Every frontier model API ships Python first. Every major agent framework — LangChain, LangGraph, CrewAI, AutoGen, Haystack — is Python. The academic pipeline runs on Python. When a new technique emerges in the research literature, a Python implementation appears within days.
Strengths for AI Agents
- Unmatched AI/ML ecosystem: PyTorch, TensorFlow, HuggingFace Transformers, LangChain
- First-class SDK support from every frontier model provider (Anthropic, OpenAI, Gemini)
- Asyncio enables I/O concurrency without blocking the event loop
- Dynamic typing accelerates prototyping speed — iterate in minutes, not hours
- RAG pipelines, vector stores, fine-tuning pipelines are all Python-native
- Largest developer community and talent pool
- Jupyter notebooks for agent experimentation and evaluation
Weaknesses for AI Agents
- Global Interpreter Lock (GIL) prevents true CPU parallelism — one thread executes at a time
- High memory overhead: 50–100MB baseline, grows with dependencies
- Cold start latency of ~1200ms makes it poor for serverless/edge deployments
- Dynamic typing causes runtime errors that statically typed languages catch at compile time
- asyncio complexity increases sharply in multi-agent coordination
When you call tokenizer.encode() in Python, you are already running compiled Rust code via a C FFI bridge. The AI ecosystem is already polyglot at its foundations.
🐹 Go — The Orchestration Layer
Go was designed at Google to solve exactly the class of problems that AI agent orchestration presents: managing thousands of concurrent lightweight tasks, each doing mostly I/O work, with clean error propagation and simple deployment. Its concurrency model is not bolted on — it is the language’s core identity.
Strengths for AI Agents
- Goroutines: millions concurrently at ~2KB each — ideal for tool fan-out
- Channels model agent-to-agent communication patterns naturally
- No GIL — true parallelism across all CPU cores
- Compiles to a single static binary — trivial container deployment
- Sub-50ms cold start — perfect for serverless agent triggers
- Built-in race detector catches concurrency bugs before production
- 10-20MB memory footprint vs Python’s 50-100MB
- HTTP/2, gRPC, and WebSocket support in the standard library
Weaknesses for AI Agents
- Thin AI/ML ecosystem — no PyTorch equivalent exists
- Garbage collector introduces occasional latency spikes under memory pressure
- Verbose error handling — no ? operator, no exception-based shortcuts
- Native LLM SDK support lags Python by versions and features
- Slower development velocity for exploratory or experimental work
Why Goroutines Change Agent Architecture
The goroutine is Go’s signature contribution to concurrent programming. A goroutine costs approximately 2 kilobytes of stack memory at creation, grows as needed, and is scheduled by the Go runtime — not the OS. This means spawning 10,000 goroutines is not only possible, it is idiomatic.
For AI agent systems, this matters enormously. Consider a multi-agent orchestrator that fans out to 200 tool calls simultaneously — each tool calling an external API, a database, a vector store. In Python, you use asyncio coroutines (single-threaded). In Go, you spawn 200 goroutines and the scheduler handles true parallelism across all CPU cores.
The highest-performance production MCP (Model Context Protocol) servers being deployed in enterprise environments are Go. A single Go MCP server comfortably handles 50,000 concurrent tool requests on a single instance.
⚙️ Rust — The Runtime and Memory Layer
Rust occupies a unique position: it delivers C-level performance with memory safety guaranteed at compile time — no runtime overhead, no garbage collector, no surprises. For the layers of an AI system where performance is the product — inference, tokenisation, vector similarity search, embedding computation — Rust is not just competitive. It is in a different category.
Strengths for AI Agents
- Eliminates data races at compile time — fearless concurrency with zero runtime cost
- Zero-cost abstractions — iterator chains as fast as raw C loops
- 3–8MB memory footprint — unmatched density for high-scale deployments
- No GC pauses — predictable tail latency, crucial for real-time agent systems
- WASM compilation — run agent logic at the edge on Cloudflare Workers / Fastly Compute
- Candle / Burn — native ML inference frameworks without a Python process
- HuggingFace tokenizers are Rust under the hood — used by every LLM developer
- Best-in-class async with Tokio, matching Go goroutines in throughput
Weaknesses for AI Agents
- Steepest learning curve of any mainstream language — borrow checker takes weeks to internalise
- Borrow checker friction slows exploratory and prototyping work significantly
- Compile times can be significant for large projects (mitigated by incremental builds)
- AI/ML ecosystem is years behind Python’s depth and breadth
- Overkill for orchestration-only workloads where Go would suffice
- Smaller talent pool makes hiring more challenging
Where Rust Is Already Powering AI
Rust’s presence in AI infrastructure is larger than most developers realise, because it operates at layers below where most engineers work. The HuggingFace tokenizers library—used by virtually every LLM application in the world—has its core written in Rust with Python bindings. Anthropic uses Rust in performance-critical inference infrastructure. Candle, HuggingFace’s native Rust ML framework, runs LLaMA, Mistral, and Whisper without a Python process.
Rust is the only language among these three that compiles to WebAssembly with near-native performance. For AI agents deployed at the edge—running on Cloudflare Workers, Fastly Compute, or browser environments—Rust is the only serious option.
Head-to-Head: The Numbers That Matter
Raw Performance Comparison
These figures represent realistic single-instance benchmarks for a simple JSON API endpoint — the kind used for agent tool servers — on commodity cloud hardware (4 vCPU).
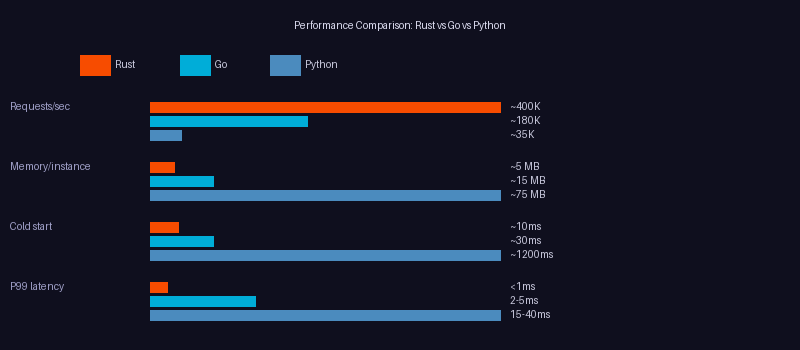
Head-to-Head: The Numbers That Matter
Raw Performance Comparison
These figures represent realistic single-instance benchmarks for a simple JSON API endpoint—the kind used for agent tool servers—on commodity cloud hardware (4 vCPU).
| Metric | ⚙️ Rust (Axum) | 🐹 Go (net/http) | 🐍 Python (FastAPI) |
|---|---|---|---|
| Requests / second | ~400K | ~180K | ~35K |
| Memory / instance | ~5 MB | ~15 MB | ~75 MB |
| Cold start time | ~10 ms | ~30 ms | ~1,200 ms |
| P99 latency | < 1 ms | 2–5 ms | 15–40 ms |
| Binary size | ~8 MB | ~12 MB | ~300 MB+ |
These numbers are illuminating, but context matters. For an agent making five LLM calls per user request, adding 40 ms on top of a two-second LLM latency is effectively invisible. However, for a high-frequency tool server processing millions of requests each day, the difference between 35K and 400K requests per second translates directly into infrastructure cost.
Decision Matrix — What to Use When
Score: 5 = Excellent Fit • 4 = Good Fit • 3 = Adequate • 2 = Poor Fit
| Use Case | ⚙️ Rust | 🐹 Go | 🐍 Python |
|---|---|---|---|
| LLM Orchestration Chaining prompts, managing context |
3/5 | 4/5 | 5/5 |
| Multi-agent Coordination Spawning and managing sub-agents |
4/5 | 5/5 | 4/5 |
| Tool / MCP Server High-throughput API endpoints |
5/5 | 5/5 | 3/5 |
| Inference / Model Serving Running LLMs & embeddings |
5/5 | 3/5 | 4/5 |
| Vector Store / Memory Layer Similarity search at scale |
5/5 | 4/5 | 3/5 |
| Rapid Prototyping Proving an agent concept fast |
2/5 | 3/5 | 5/5 |
| Streaming Responses Real-time token streaming |
5/5 | 5/5 | 3/5 |
| Edge / WASM Deployment Running agents at CDN edge nodes |
5/5 | 3/5 | 2/5 |
| ML Experimentation Fine-tuning & evaluation |
2/5 | 2/5 | 5/5 |
| Serverless Functions Lambda / Cloud Run triggers |
5/5 | 5/5 | 2/5 |
What Production AI Systems Actually Look Like
The most mature AI agent architectures in production today are not monolithic. They are layered systems where language choice depends on the requirements of each layer. The following reference architecture reflects what leading AI companies are building today.
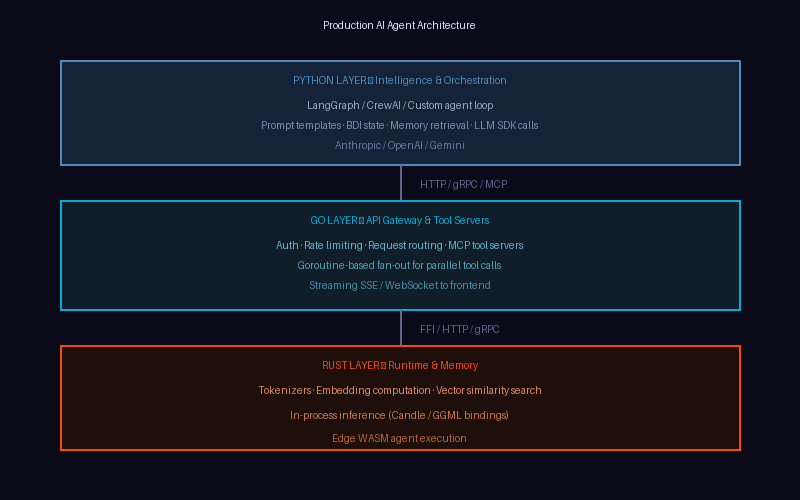
This is not theoretical. Qdrant—one of the leading vector databases in the AI ecosystem—is written in Rust. Its Python and Go clients communicate with a Rust core. The HuggingFace Tokenizers library used daily by Python developers is also powered by Rust under the hood. When you call tokenizer.encode() in Python, you are executing compiled Rust code through a C FFI bridge.
Use Python when you’re working at the Intelligence Layer—reasoning, prompt engineering, tool selection, and agent logic. Use Go when you’re building the Coordination Layer—API gateways, concurrency, streaming, and orchestration. Use Rust when you’re developing the Execution Layer—where performance, memory efficiency, and microsecond latency matter.
Final Verdict — Three Languages, Three Roles
There is no winner in this comparison—and that is the point. These languages are not competing; they are complementing each other. Choosing a single language for an entire AI agent stack is a false dilemma that experienced AI engineering teams have already moved beyond.
🐍 PythonTHE INTELLIGENCE LAYER
|
🐹 GoTHE COORDINATION LAYER
|
⚙️ RustTHE EXECUTION LAYER
|
If You Must Choose One
If your constraint is team size, hiring speed, or time-to-market—and you must pick a single language—the decision is straightforward.
Choose Python. Its ecosystem advantage is overwhelming. Every frontier model API, every major agent framework, and every evaluation library is Python-first. You’ll prototype faster, hire more easily, and ship features with less friction.
Choose Go. Tool servers, API gateways, agent runners, streaming services, and distributed systems benefit from Go’s concurrency model, simplicity, and excellent production characteristics.
Choose Rust. Inference engines, vector databases, edge execution, and performance-critical systems demand Rust’s memory safety, predictable latency, and near-native execution speed.
🚀 Career Signal for 2026
The AI engineers most in demand are not those who master a single programming language. They are the engineers who understand the AI agent stack well enough to know which language belongs to which layer and can move confidently between Python, Go, and Rust. The architecture above is more than a technical blueprint—it is a roadmap for the skills that define modern AI engineering.